SapeAOB, Andai’ puro sapeando mi código oe!
Finalmente era hora, era hora de retomar la práctica con C++ porque, why not? Rust para mi sigue siendo el lenguaje que más prefiero, pero C++ está dentro de las categorías de los lenguajes que también disfruto. Pero para volver a tomarlo en serio, era necesario crear un proyecto nuevo, y así surgió sapeAOB, (una mezcla entre sapeao’ y AOB - Array of Bytes), una microlibrería que permite encontrar patrones de bytes escrita en C++17.
First and foremost: Modern C++ is nothing like Uni* C++
Primero que todo, es necesario sacarse de la cabeza que C++ es “C con clases”. Quizás esto fue cierto hace un tiempo (probablemente en sus inicios), pero este lenguaje ha mutado demasiado (para bien o para mal) comparado con C, y estoy casi seguro que cualquier persona que siga creyendo tal aseveración, al segundo que vea un extracto de C++17 o posterior, se dará cuenta de esto también, porque existen un montón de tecnologías nuevas.
* con Uni C++ me refiero al C++ enseñado en la universidad.
template <class it, std::size_t... Indexes>
static inline constexpr bool
compare_(it arr, std::index_sequence<Indexes...>) noexcept {
return (... && compare_one_(arr, Indexes, Pattern));
}
Un par de profesores de la U pecaron diciendo esto al introducir el lenguaje
al ramo, pero está bien, quizás no es su deber estar al día cuando ese no es el
enfoque del curso (en mi opinión si lo es pero who cares).
Pero, ¿qué tiene de distinto a C, aparte de sus clases?
Bueno, un montón, tantas que en un blogpost sería imposible enumerarlas. Al
menos, lo que noté en mi estadía universitaria, principalmente se usaba C++99,
el cual a estas alturas es más de 20 años viejo. En la actualidad, aún se
ocupan bastante los punteros, pero el enfoque ha sido en intentar alejarse un
poco del new y el delete, siendo emplazados por el enfoque
RAII
usando estructuras tales como std::unique_ptr<T> o std::shared_ptr<T>, que
facilitan mucho el manejo de memoria y evita cometer grandes errores usando
contadores de referencia. También hay muchas adiciones como iteradores,
templates, etc. Tantas que nisiquiera intentaré referenciarlas, pero te
invito a darle una oportunidad nueva a este lenguaje si es que te interesa el
performance, y cppreference es un gran sitio para
comenzar.
Ya pero, ¿Y en qué afecta esto al Boca (o a SapeAOB)?
Probablemente existan muchas librerías que se enfocan en buscar ciertos valores contiguos en un array, pero mi enfoque en particular estaba en funciones generadas a tiempo de compilación, de lo cuál hablaremos ahora.
Rust & C++ vs. the interpreted world
Lenguajes interpretados, a estas alturas has escuchado mucho de éstos, quizás no categorizados como tal, pero en el campo laboral son los lenguajes que más frecuentemente encuentras: Python, Javascript, Java (kinda), Shellscript (bash), etc. Todos estos lenguajes tienen una similitud, y es que existe un software que se encarga de procesar el código que uno escribe e interpretarlo al mismo tiempo, y sin la existencia de este software el código “por si solo” no podría funcionar.
No hay nada malo en esto, esto ha permitido que el multiplataforma sea una garantía a estas alturas, son en general mucho más fáciles y rápido de iterar y son super cómodos, pero tienen 2 problemas esenciales que afectan en escenarios muy específicos: como ya se mencionó, dependen del software que los interpreta y por lo tanto la segunda, al tener una capa extra (y grande) de abstracción, son más lentos.
Comenzar una holy war de que tipo de lenguaje es mejor tampoco es mi intención, soy un fiel creyente de que cada lenguaje tiene su utilidad (Use the right tool for the job). Me encanta hacer análisis de datos en Python, y también me encanta escribir software bajo nivel en Rust, ¿Por qué no podría disfrutar de ambos?
Entonces, ¿por qué estamos hablando de ésto?
Bueno, como ya se mencionó dos veces, estos lenguajes interpretados requieren de un software que los interprete, y por lo tanto, a grandes rasgos, tienen una sola fase: Runtime, o tiempo de ejecución. Es decir, este programa sólo existe cuando el intérprete lo interpreta valga la redundancia. Generalmente estos lenguajes son muy dinámicos, permiten hacer cosas muy locas con la manipulación de objetos para incrementar sus habilidades a Runtime, y por lo menos en mi mente, me hacía pensar que solo existe una fase en la etapa de programación, lo cual es muy relevante para el tópico siguiente.
Compile time, escribiendo los bytes que tu CPU va a leer.
C, C++, Rust, Go son algunos de los lenguajes que se me vienen a la cabeza. Estos son lenguajes compilados. ¿Qué quiere decir esto? Bueno, que para que tu computador pueda ejecutarlos, después de que tú como programador termine de escribirlo, tienen que pasar por un proceso de traducción, este proceso es el que se llama compilar (Bieeeen a grandes rasgos, hay muchos detalles que no valen la pena escribirlos acá). ¿En qué consiste este proceso? Bueno, primero el compilador lee tu código, lo convierte a un formato que él entienda (sí, el código es para que los humanos lo entiendan, no tu computador), y luego genera el código ensamblado que es el que finalmente leerá tu computador para ser ejecutado. Una vez tu compilaste tu programa, se obtiene lo que se llama un binario, que es básicamente a lo que tu haces doble click para abrir un programa. Este binario, contiene toda la información necesaria para que tu sistema operativo y tu CPU pueda ejecutarlo, es decir, no depende de un tercer software para poder ejecutarlo (no es interpretado) y por lo tanto posee dos fases: Compilación y Ejecución (Runtime). Es más, es aquí donde se pone interesante y la razón por la cuál SapeAOB fue escrito (mansa’ intro).
Sapeando tu código.
Los binarios contienen toda la información necesaria para ser ejecutados, y por lo tanto, no necesitas mantener el código fuente para ejecutar el programa a diferencia de los lenguajes interpretados. (pero si lo quieres seguir mejorando, obvio que lo necesitarás lol).
Estos binarios pueden ser “desensamblados” de tal forma que puedas leer su código, pero a diferencia del código fuente, solo tendrás acceso a lo que el compilador escribió por ti, el cual corresponde al lenguaje assembly. Por lo menos, yo recuerdo que en la Universidad nos metían mucho miedo sobre este lenguaje, que necesitabas ser un verdadero pro para poder escribir en él, y probáblemente sea cierto si es que quieres escribir un programa desde cero (lo cuál es bastante poco práctico hoy en día a no ser que quieras extraer hasta la última gota de performance que puedas desde tu CPU, lo cual no solo requiere conocer el lenguaje si no que las capacidades específicas de tu procesador), pero para leerlo e interpretarlo no necesitas ser un real pro, solo necesitas estudiarlo un poco (y para escribir shellcodes también).
El objetivo de SapeAOB es encontrar un patrón de bytes en un arreglo. Los binarios pueden ser leídos como un montón de bytes (que a la vez contiene las instrucciones necesarias para ser ejecutado). Cuando hacemos modificaciones a los binarios, estos en general se hacen a un conjunto de instrucciones específicas (por ejemplo, que en vez de que una función sume algo, lo reste). Estas instrucciones se pueden ir moviendo cada vez que compilamos nuevamente el programa original y por lo tanto, sus offsets varían. Es por esto que es mejor usar patrones de bytes (informalmente array of bytes) para encontrar estas instrucciones específicas independiente de los futuros cambios que se hagan en otras secciones del código (y por eso, sapeamos el código 😅).
En el contexto del game hacking, como mencioné en un blogpost pasado, es importante tener la habilidad de usar AoB’s para que las inyecciones sean update-proof.
Detalles de la implementación.
Hasta ahora hemos hablado mucho sobre el contexto y poco sobre la intención y la forma en la que está escrita SapeAOB. Como se mencionó en la sección donde se definían los lenguajes interpretados, los lenguajes compilados poseen 2 fases esenciales durante su vida: Fase de compilación, y fase de ejecución. Como en la actualidad estamos mucho más acostumbrado a los lenguajes intepretados que a los lenguajes compilados, como ya mencioné, cuesta pensar en estas dos fases como algo separado, por lo menos en mi cabeza el proceso de “compilar” tu software era una tarea más que un proceso por sí solo.
The fun stuff: Generating code at compile time
Los templates llevan bastante tiempo en C++, cada vez que usabas algo como
std::vector<int> estabas usando un template donde el tipo que reemplazabas
eras int. ¿Qué significaba esto para el compilador? Bueno, cuando tu escribes
una función que usa templates, lo que le indicas al compilador es que por cada
aparición de un tipo nuevo que ocupa esta clase, función o estructura, debe
generar el código específico para ser usado por ese tipo. Todo este código se
genera en el tiempo de compilación y una de las grandes ventajas es que permite
al compilador usar optimizaciones específicas para cada tipo de forma más
inteligente.
Ejemplo
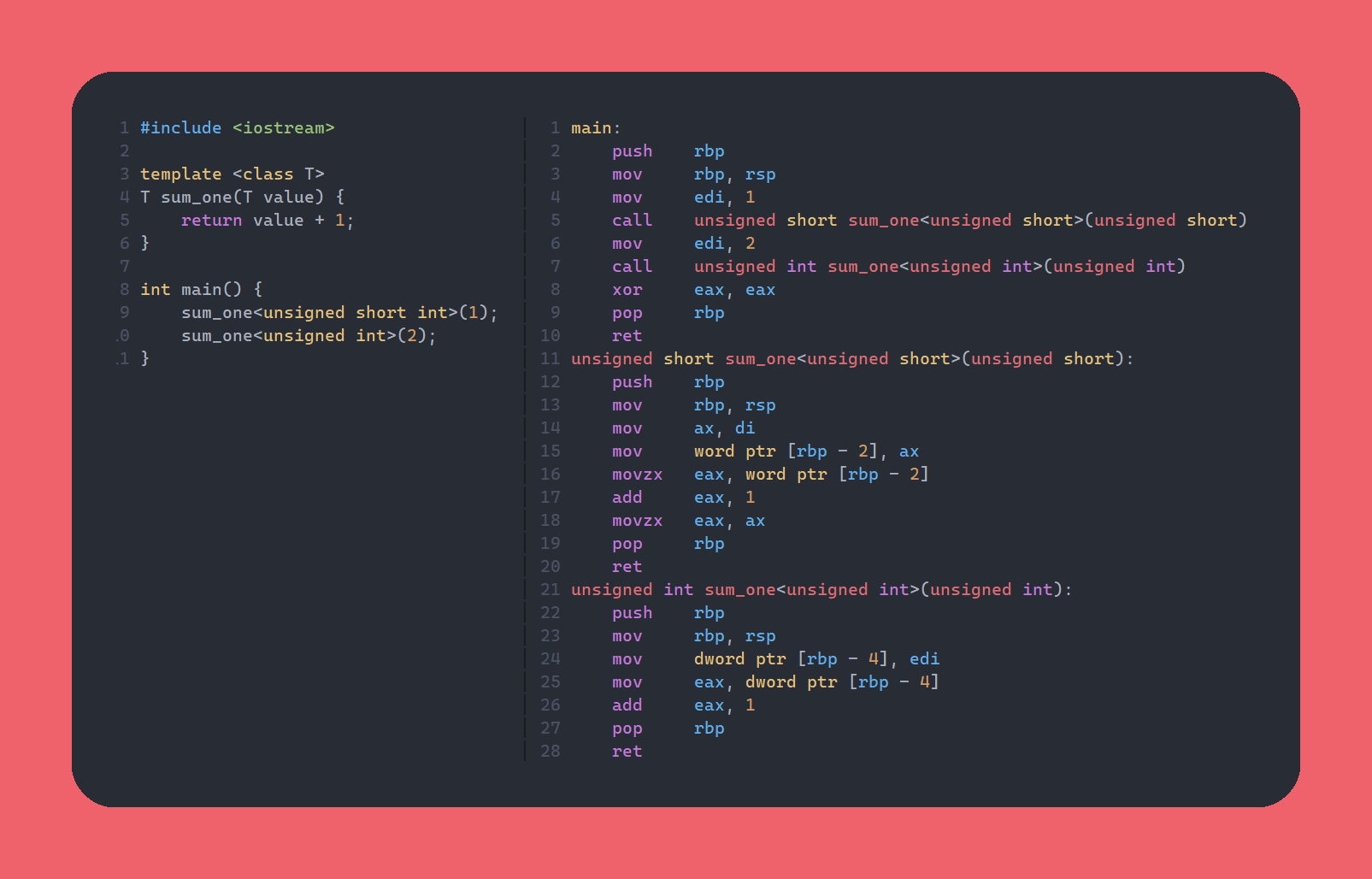
Bear with me, el código generado no es complejo. Si te fijas en el lado derecho
existen 3 funciones (o labels), main que corresponde de forma homóloga a la
del código de la izquierda, unsigned short sum_one(unsigned short) y otra
unsigned int sum_one(unsigned int). Como te puedes fijar, el compilador creó
2 funciones sum_one en vez de una como nosotros escribimos. Fijándonos en
lo esencial, en main primero se hace un mov al registro (algo así como
variable) edi del valor 1 y luego se llama a la versión unsigned short, y
como se puede apreciar en la función en sí, se guarda un entero de tamaño 2 con
la operación mov word ptr [rbp - 2], ax, ya que word corresponde a variables
de tamaño 2, en cambio en la de unsigned int, se utiliza mov dword ptr [rbp - 4], edi, donde dword corresponde a una variable de tamaño 4. Es decir, el
compilador generó código específico para cada uno de los tipos por nosotros lo
que *en general* genera un mejor rendimiento. Esto es el equivalente a que
nosotros hubiésemos escrito ambas versiones a mano en C.
Back to the details.
Sabiendo sobre estas fases de compilación, y como funcionan a nivel bien básico los templates, es que comencé a escribir SapeAOB. Durante el desarrollo seguí dos approach:
- Corta fuego
- Bitwise operations
La versión cortafuegos básicamente consistía en una larga concatenación de &&
para verificar que un arreglo siguiera un patrón. Por ejemplo, si tenemos el
patrón 0xAA, 0xBB, 0xCC, lo que hacía era generar un “if” bien largo que se
escribe como if (arr[offset] == 0xAA && arr[offset+1] == 0xBB && arr[offset+2] == 0xCC). La gran ventaja de este approach, es que al igual que en varios
lenguajes, este tipo de && concatenados generan un “cortafuegos”, en el
sentido de que a penas uno sea falso, se corta la verificación de todo el
resto.
El otro approach, fue generando operaciones binarias usando xor y and. Los
detalles no son tan importantes, pero básicamente se verificaba que al hacer
xor estos bits se anularan y si es que era 0, significaba que son iguales.
En un principio pensé que hacer este cambio provocaría mejoras, pero sucedió lo contrario. Desde mi perspectiva creo que esto provocaba un peor rendimiento debido a que sí o sí verificaba todo el patrón antes de decidir si era realmente un match o no, a diferencia del primer approach que simplemente cortaba la verificación a penas el primer byte distinto se identificara.
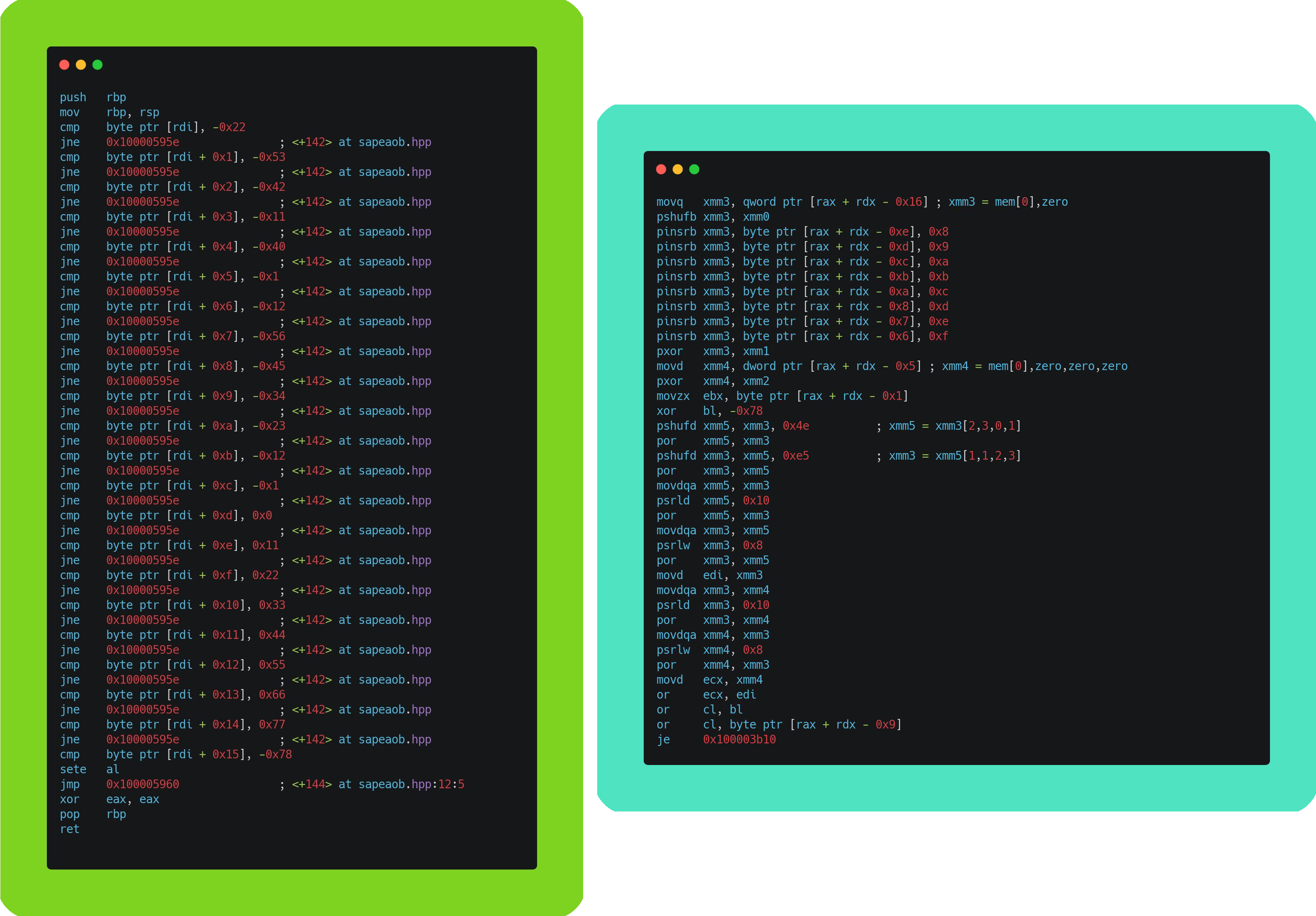
Habiendo escrito la función esencial encargada de ser generada a tiempo de compilación, después bastó con generar la capa de abstracción que finalmente ocupará el usuario al hacer uso de esta librería. Todo este estudio, para finalmente escribir algo tan simple como:
std::uint8_t test_arr2[] = {0xCC, 0xFF, 0xAA, 0xEE, 0xCC};
sapeaob::pattern<0xAA, sapeaob::ANY, 0xCC> p{};
result = p.scan_match(test_arr2, sizeof(test_arr2));
CHECK(result == reinterpret_cast<std::uintptr_t>(test_arr2 + 2));
sapeaob::ANY corresponde a la keyword que actua como wildcard, es decir, el
segundo byte puede ser cualquier byte.
Como se puede apreciar en el ejemplo, el constructor de sapeaob::pattern no
recibe ningún parámetro en sí, estos parámetros son pasados a través de la
especificación del template, por lo que esta información es guardada a
tiempo de compilación, y por lo tanto las funciones para comparar el arreglo
con un patrón son generadas por tí. Pretty nice huh?.
Oye y, ¿valió la pena experimentar con esto?
Pero por supuesto! Siempre hay una buena razón para aprender de algo, hacer
experimentos y profundizar conocimientos. Además, resultó que sapeaob es
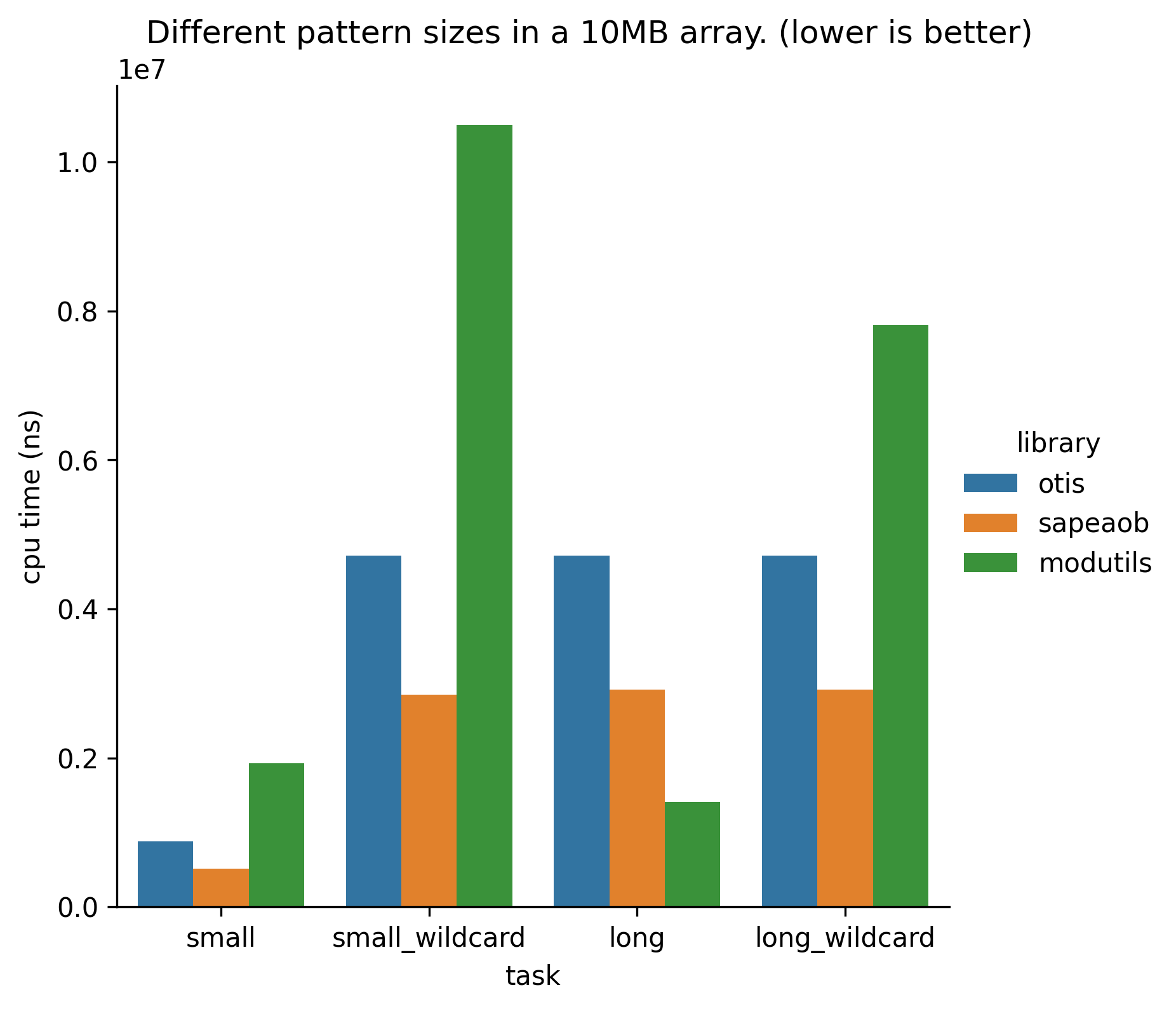
bastante rápido!
Frans Bouma, un conocido modder de freecameras (al cual respeto mucho) fue lo suficientemente amable como para prestarme su implementación para así poder hacer benchmarks. Además, también lo comparé con la librería open source de Silent — un conocido modder de la escena de GTA que ha hecho importantes parches — ModUtils y resulta que sapeAOB es más rápida en la mayoría de los casos comparados con estas librerías!
En fin, este post fue bastante extenso y bastante técnico, pero espero que como lector hayas podido llegar hasta el final, y si no, no importa, también me gusta escribir estos posts para mi mismo, quizás en el futuro lo leeré nuevamente y me re-encantaré con la programación una vez más.